Linux Tracing - Kprobe

自各类计算机程序开始被编写、运行开始,我们就一直想通过各种方式来了解它的执行过程和状态从而判断计算机程序运行的行为和效率。作为被使用最广泛的操作系统,Linux 经过多年发展,拥有了各类工具和组件来实现对用户程序以及内核程序的追踪,这些组件组成了 Linux 的追踪(Tracing)系统,它的魔力令人着迷。
本文将从最基础也是最灵活的 Kprobes(Kernel Probes) 入手,了解 Linux Tracing 系统的设计(本文基于 linux kernel v6.15.4)。
1. 设计尝试
在了解 Kprobes 之前,我们也许可以先设想一下,对于一段程序,如果我们想要了解其执行过程中的每一步,其运行前后程序状态的变化,需要怎么做?这个问题值得思考,事实上在明确更具体的限定条件以前,我们无法作答,因为该程序的类型并不明确。
我们可以分析如下几种情况:
- 假如是裸机程序,由于常见的 CPU 都提供了调试中断或调试异常机制,由此我们可以让程序单步执行,但同时也需要类似硬件调试器的工具来获取暂停后各寄存器的状态
- 假如是运行在操作系统(如 Linux)中的程序,不论是用户态或内核态程序,我们都可以在每一条或需要的任一条指令前后插入软件中断指令使 CPU 陷入中断,进而我们可以在中断处理程序中获取当前程序状态
- 假如是运行在虚拟机(例如 JVM)中的程序,则需要借助特定虚拟机的能力,实现虚拟环境下的 “软件中断”,从而暂停程序运行,这非常依赖具体的虚拟机实现
不过,基于上述分析,我们发现不论是哪种场景下,为了设计一个能了解任意一段程序的执行过程和状态的工具,都需要实现以下两个核心设计要求:
- 该工具必须拥有随时暂停以及恢复程序运行的能力
- 该工具可以作为外部观察者观察当前系统的状态
现在,我们对前面的问题加以限定:我们期望能观测在 Linux 下运行的任意用户态或内核态程序。映射到设计要求:
- 暂停/恢复程序运行:需要能动态的在程序的代码段特定位置中插入软件中断指令,使 CPU 陷入中断
- 观察系统状态:在中断处理程序中读取并保存当前的寄存器上下文
显然,为了满足上述设计要求,我们的工具需要有极高的权限从而实现对正在运行的程序进行修改和探测,这要求工具必须运行在内核态。一旦满足了上述基础要求,对工具进行不同方向上的扩展,就能实现差异化能力:
- 为程序创建用户态接口,可支持对程序的运行状态和寄存器值进行控制,这就实现了调试器的功能
- 为程序预留编程扩展接口,可同时对多个程序进行大规模持续观测,这能实现对任意程序的追踪和剖析功能
2. Kprobes 案例
在了解了上述设计要求和要点后,我们也许能更容易理解 Kprobes。首先,Kprobes 能够动态的切入几乎任意内核程序(除了包含在blacklist中的那些)并收集信息(甚至修改寄存器值)。对应的 Uprobes 则可以对用户态程序进行动态切入,本文暂不涉及 Uprobes。
当切入点被调用前后,Kprobes 会执行自定义的 handler 程序。通常,Kprobes 的注册、注销以及 handler 程序的定义都被包含在内核模块中,这样对定义了 Kprobes 的内核模块进行加载时,Kprobes 就能被插入内核中了。
如下是一个十分简单的 Kprobes 内核模块代码案例,通过该案例我们就能基本了解 Kprobes 的使用:
1 |
|
如上所示是一个简单的 Kprobes 内核模块,它能够在
sys_openat 符号(即 open
系统调用)被调用时尝试打印
filename。其核心在如下三部分:
- 定义 kprobe 结构,并写入
kp.symbol_name = "sys_openat";以及kp.pre_handler = handler_pre;:这定义了 Kprobes 的挂载点符号和 handler 程序,pre_handler 代表将在挂载点被调用前执行 - 注册 Kprobes:
register_kprobe(&kp)将 kprobe 结构注册进 Kprobes 框架中,触发生效 - 注销 Kprobes:
unregister_kprobe(&kp);将 kprobe 结构移除 Kprobes 框架
此外,handler 函数传入的参数 pt_regs *regs
包含了当前的寄存器信息,这是一个平台相关参数,使用者需要根据体系结构和
ABI 的差异来选择从正确的寄存器中获取需要的值。
通过上述代码可以看到 Kprobes 框架的抽象程度很高,使用简单。接下来我们从实际设计的角度进一步探寻其原理。
3. 设计原理
在深入 Kprobes 的设计原理之前,我们不妨再次以主观的视角来进行思考:假如要设计实现上一节所描述的 Kprobes 能力,作为 Kprobes 框架需要解决哪些问题?
首先,最核心的点是,需要将 handler 的调用插入所监控的切入点,在第一节我们已经分析过,可以通过在切入点前后插入软件中断指令使 CPU 陷入中断并在中断处理程序中调用 handler,这样在执行完成后能够随中断机制再次回到切入点位置。此外,可以想一想,除了软件中断我们能不能直接插入一条跳转指令使程序流直接跳转到 handler 呢?这也许省去了中断处理的开销,但也需要考虑如何跳回。
其次,我们发现在前一节的代码中,有一个 struct kprobe
结构来组合包括切入点符号、处理程序等等的关键元素,这些关键元素聚合在一起才能完整的描述一个
kprobe。那么,作为一个面向众多使用者的框架,Kprobes
必须考虑如何管理这些kprobe结构,从而使每一个注册的 kprobe
都能顺利执行,也能在不在需要的时候被注销。这涉及到对kprobe结构的访问、存储、和增删。
最后,还需考虑一些看似边缘实则很容易产生的情况,例如多个程序并发的注册、注销 Kprobes 时如何确保并发安全?以及如果尝试为同一个符号注册多个不同的 kprobe 会怎么样?还有,作为对系统运行拥有绝对控制权的内核,考虑是否可以不止将符号作为切入点,是否能将程序的任意一行作为切入点?
随着对这些问题的思考,接下来我们进入原理分析。
3.1 管理 Kprobes
从最简单的开始,对于注册的多个 kprobe 结构,Kprobes
框架需要有一套机制来维护和管理这些
kprobe,以便于在切入点被命中时能快速检索到并执行实际的自定义操作。
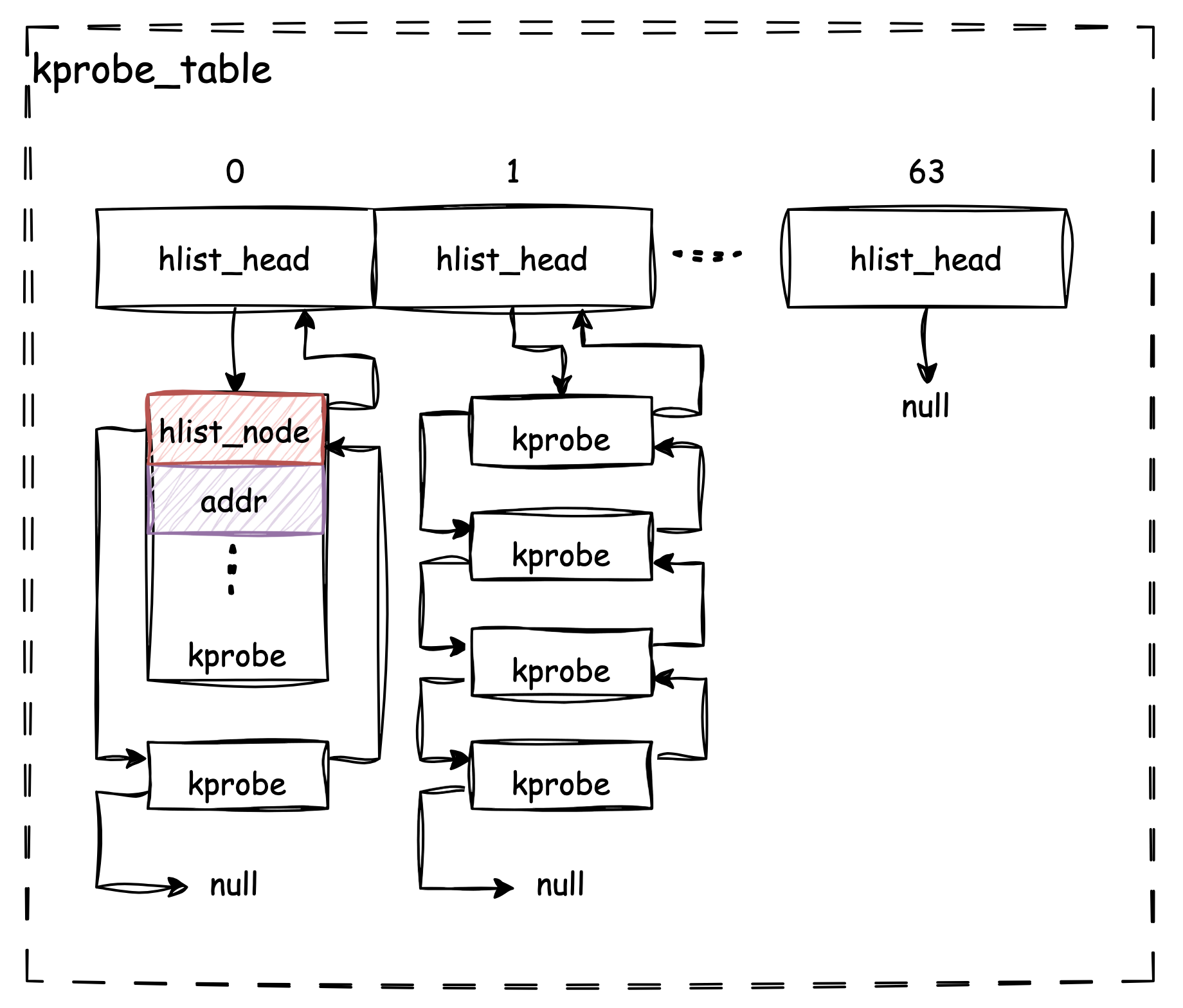
事实上,在 Linux Kprobes 的设计中,是通过一个 Hash Table 来管理所有
kprobe 的:
1 | // kernel/kprobes.c |
显然,kprobe_table 是一个拥有 64 个 slot
的线性数组,其每一个数组元素是一个 hlist_head
类型的值,hlist 是一个常见的内核数据结构,用于构建通用 Hash
Table。hlist_head 指向一个链表,其链表元素的类型为
hlist_node。事实上
struct hlist_head name[1 << (bits)]
这类定义就是一个标准 Hash Table 的模版定义(更多内容可参考这里)。
因此我们可以将 kprobe_table 视为 64 个 hash
buckets,为了应对 hash collision,每一个 bucket
中实际存放了一个长度不一的链表。那么为了让 struct kprobe
顺利成为 hlist 中的一个元素,其结构内部势必需要包含一个
hlist_node 来作为连接节点,参考源码定义,的确如此:
1 | // include/linux/kprobes.h |
此外,既然 kprobe_table 是一个 Hash
Table,那么对于一个新的 kprobe,基于什么作为 Hash Key
来判断将其插入的位置呢?答案是通过切入点的 addr。
1 | // include/linux/kprobes.h |
回忆第二节的示例代码,我们仅为 kprobe 设置了
kp.symbol_name = "sys_openat";。实际上在注册的过程中会将符号名替换为相对地址并存入
kprobe,这样就可以将 addr 作为 key 来计算 slot
index 了。
综上,我们可以绘制如下示意图来描述 Kprobes 框架对 kprobe
的管理结构:
3.2 Kprobe 结构
上一节我们已经部分了解了 struct kprobe 中包含了
hlist 和 addr
两个关键字段,接下来我们一起通过讨论完整的kprobe
结构,来进一步认识 Kprobes 框架的工作方式。
1 | // include/linux/kprobes.h |
通过每个 field 的注释我们已经能够大致的了解到它们的用途。
3.2.1 切入点相关的 Fields
首先在前面的内容中已经提到过,在 kprobe
中可以指定切入点的 addr,也可以指定
symbol_name + offset 作为切入点,但 addr 和
symbol_name
是互斥关系,不能同时存在,否则注册时会报错。实际上在 kprobe
最终运作时,都是以 addr 作为实际的切入点位置,而假如指定了
symbol_name 则会经过一个转换的过程将之转换为
addr。这也证明,Kprobes
框架支持几乎在程序任意位置进行切入(在 Kprobes
框架中存在一些黑名单地址,禁止切入)。
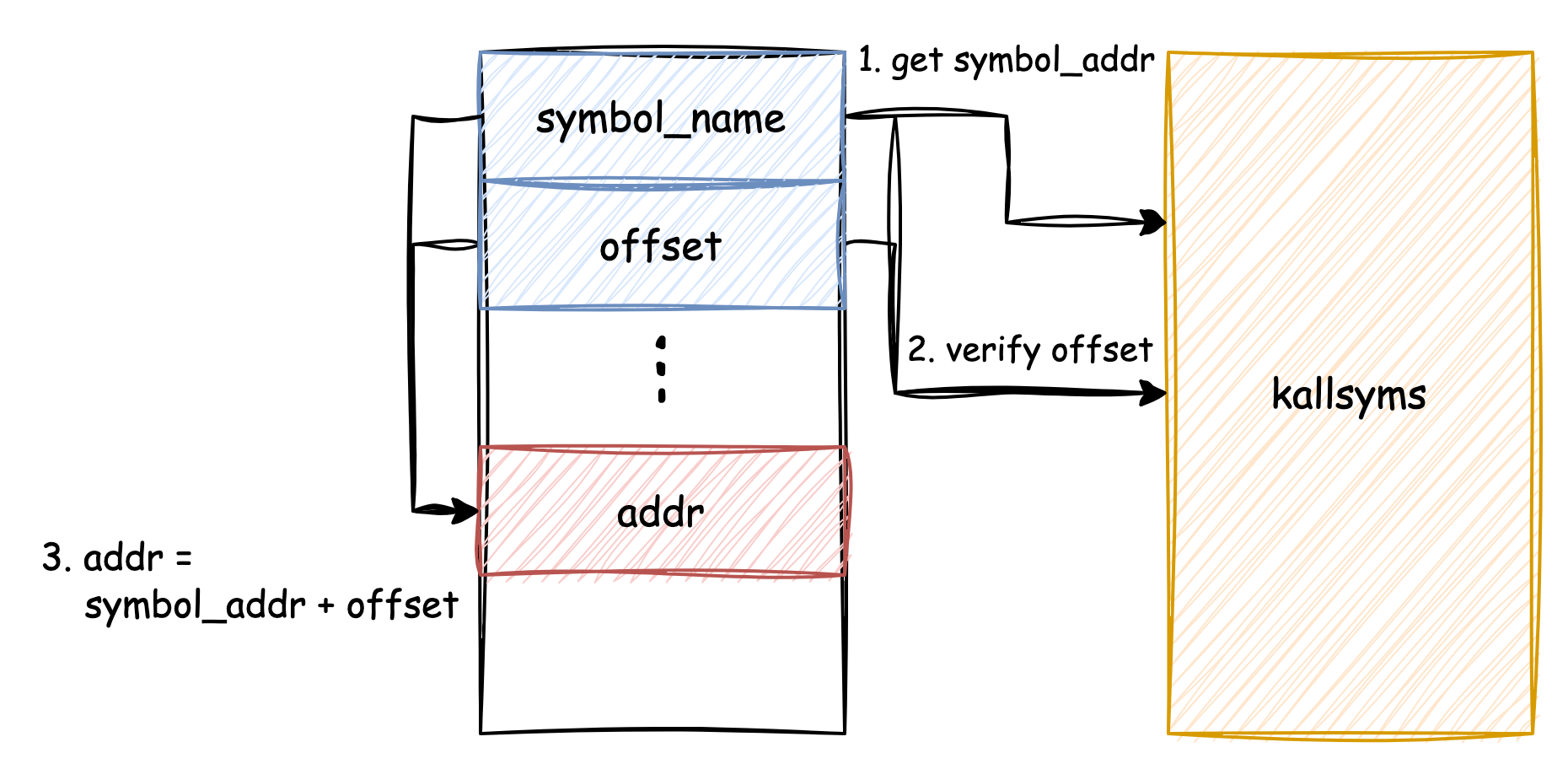
对符号到地址的转换过程依赖子系统提供的能力:根据配置不同,默认情况下内核中已导出的符号和其地址会由
kallsyms 记录并提供运行时查询。因此如果 kprobe
中通过 symbol_name + offset 的形式描述切入点位置,Kprobes
框架会通过 kallsyms 接口来对其进行验证并转换为实际的
addr。简化流程可见:
其次,pre_handler 和 post_handler
会在切入点被命中的前后被执行,简单看看它们的函数签名:
1 | // include/linux/kprobes.h |
第一个相同的参数 struct kprobe *
不多做赘述,而第二个相同的参数 struct pt_regs *
中保存了当前执行 CPU 的寄存器值。此外,根据 kprobe
文档,post_handler 的最后一个参数 flags
目前总是为零值。
需要注意的是pre_handler
还需要一个int返回值。由于 kprobe 运行在内核态,handler
程序实际上可以修改任何寄存器的值从而改变程序执行路径(例如修改 program
counter),但这非常危险,在 kprobe 文档的相关章节中建议:“对于要修改程序执行流程的内核老司机,在修改寄存器值之后记得让
pre_handler 返回非零值,进而 kprobe
框架会直接跳转到新的地址,而不再执行原切入点的指令,也不再执行
post_handler”。
对于 kprobe_opcode_t opcode; 则涉及到了 kprobe
的核心原理,即为了正确命中切入点,kprobe
框架会把切入点的原始指令暂存,并替换为 Breakpoint 指令,例如 x86
架构下的 INT3,这里的 opcode
就保存了切入点指令。更多细节我们在下一小节讨论。
相对应的,struct arch_specific_insn ainsn;
保存了与体系结构相关的额外信息,opcode
是与体系结构无关的字段,它直接保存了指令的内容。而 ainsn
进一步保存了与体系结构相关的一些信息,不同的体系结构下其实现可能存在差异,例如
x86
的实现以及 riscv
的实现。
此外,unsigned long nmissed; 存储了当前 kprobe
被触发,但未能成功执行 handler 的次数,通常情况下,这是由于该 kprobe
发生了重入(reenter),即该 kprobe 触发了另一个
kprobe。在这种情况下,handler 不会再被运行,而是记录一次
nmissed。
最后,u32 flags;
作为一个状态指示器指示了当前的各种状态,其中包括启用、禁用、已注册等等。
3.2.2 相同切入点上的多个 Kprobes
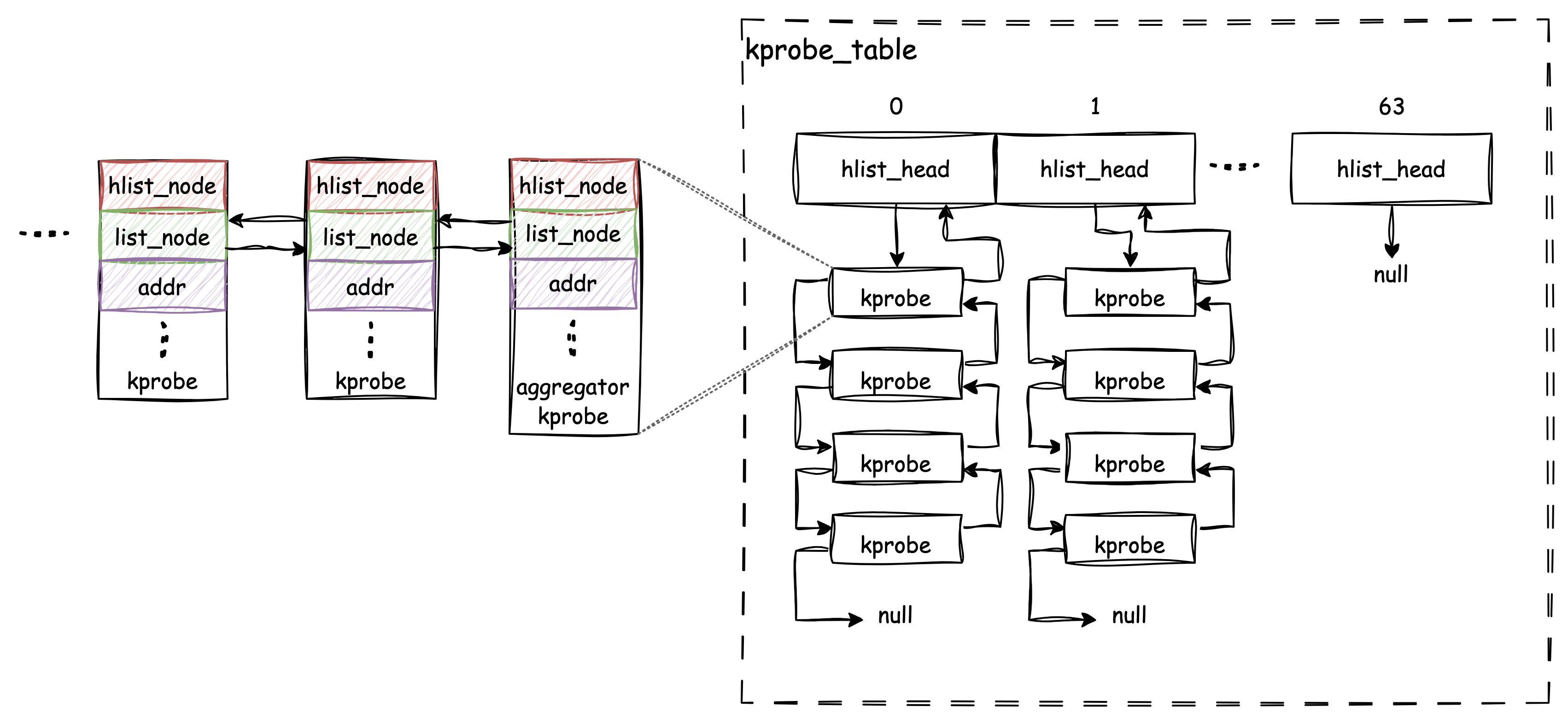
回到前面提到过的一个问题:作为一个通用的框架,假如有多个调用方期望在同一个切入点上挂载多个 kprobe,该怎么办呢?
事实上 Kprobes
框架依然采用了线性表的方式来确保这种情况能够被满足。struct list_head list;
充当了该职责,list_head
是内核中提供的双向链表结构,它非常简单的只包含了前后指针两个字段。与
hlist_head
类似,实际使用时嵌入到具体的结构中,通过计算偏移量就能取回实际的结构。
因此,kprobe 可以通过 list
字段将其他与其具有相同切入点的kropbe
通过该双向链表串联在了一起,从而当切入点被命中时,每一个
kprobe 都会被依次触发而不会被漏掉。
有趣的是,为了实现依次触发的要求,在每一个kprobe
链表的头部,会放置一个特殊的 kprobe 结构,名为
“aggregator”。它与普通kprobe 的唯一区别在于其
pre_handler 和 post_handler 会被替换为如下的
handler:
1 | // kernel/kprobes.c |
很简单的,这些 aggrator handler 实际上遍历了所有链表内的
kprobe 并实际调用它们的 handler。
同时,我们现在可以更新一下 Kprobes 框架的结构图:
3.3 命中
在前面的章节中我们已经或多或少的设计了一些切入点命中的原理。现在我们将通过更多的细节来具体了解切入点的命中,以及 handler 执行相关的原理。
我们已经知道,kprobe 框架激活某个 kprobe
后,会将其设定的切入点指令暂存,并替换为 Breakpoint
指令。首先不同体系结构下的 Breakpoint
指令是完全不同的,为了支持不同的体系结构,实际的激活动作(也就是register_kprobe()的最后一步)的实现是与
CPU 类型相关的(这里函数签名中的 “arm” 指的不是 arm CPU 而是
“装备”、“配备” 的意思):
1 | // arch/x86/kernel/kprobes/core.c |
以x86下的实现为例,text_poke 将 INT3
指令写入切入点地址中,而在此之前,原切入点指令已经通过 arch_prepare_kprobe()
被保存在了 opcode 和 ainsn
中了(保存原始指令的实现也是体系结构特有的)。
引用 Kprobes 文档的 "How Does a Kprobe Work" 章节,我们可以从描述上进一步了解完整的执行过程:
当一个 kprobe 注册后,Kprobes 框架将切入点指令复制一份,并将原始切入点的第一个字节替换为一个 Breakpoint 指令(如在 i386 和 x86_64 上的 int3)。
当某个 CPU 命中该 Breakpoint 指令时,将发生 trap,该 CPU 的寄存器被暂存,控制流通过 notifier_call_chain 被传递给 Kprobes 框架。Kprobes 框架执行与 kprobe 关联的 “pre_handler”,将
struct kprobe的地址以及暂存的寄存器传递给 handler。之后,Kprobes 对其复制的切入点指令进行单步执行(single-steps)。(直接在指令原始位置上 single-step 会更简单,但 Kprobes 框架将必须临时性移除 Breakpoint 指令。这可能会打开一个小时间窗口使其他 CPU 有可能在运行时直接掠过切入点。)
在指令被单步执行后,Kprobes 框架执行 “post_handler”(如果有的话)。之后,程序会接着切入点的位置继续执行。
这里所谓的 “命中后单步执行”,在不同体系结构下虽略有差异,但都遵循类似的流程。下图展示了 x86、arm64、riscv 三种体系结构下 Kprobes 命中的流程:
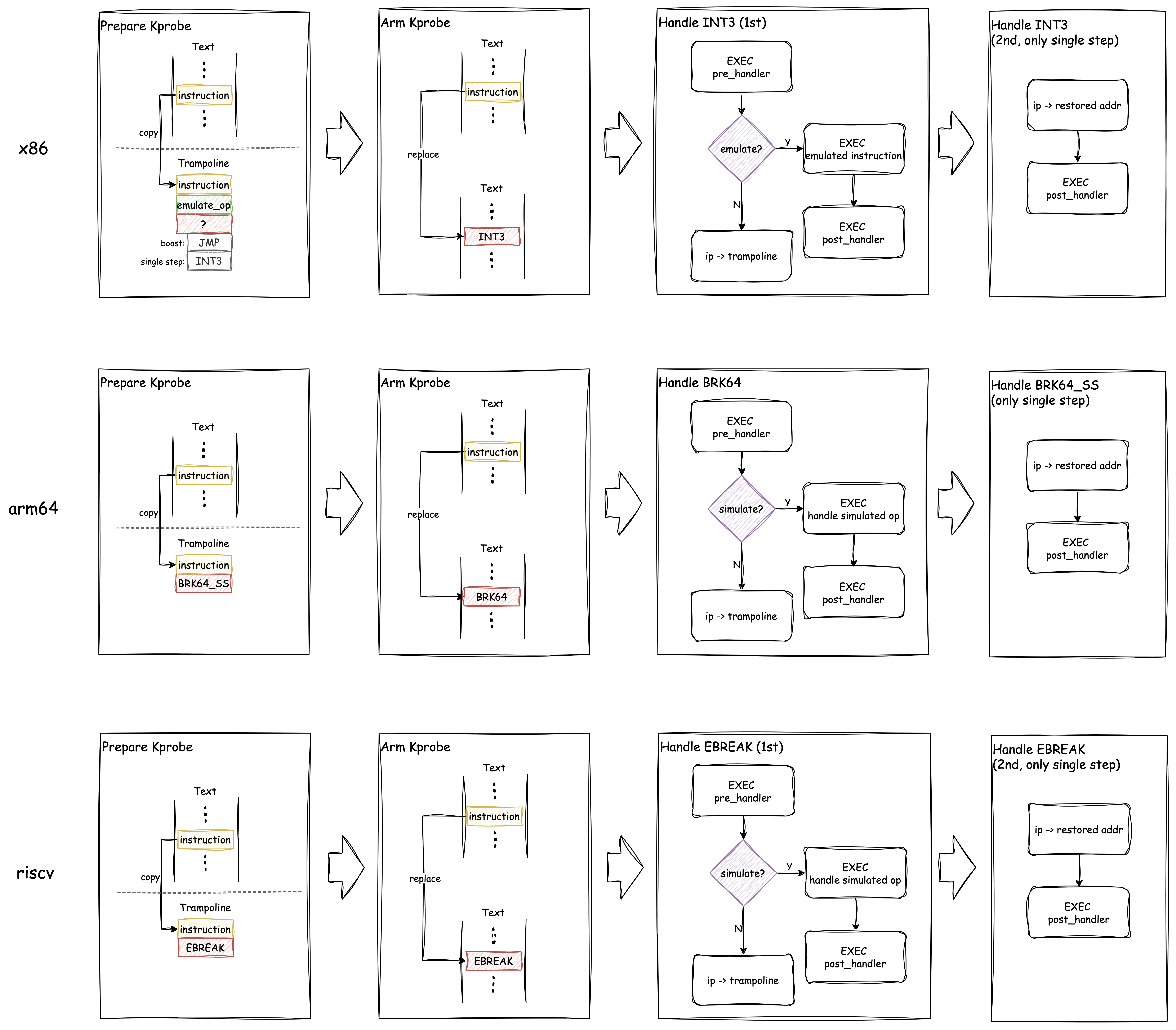
显然,对于上述三种类型的 CPU,其本质都是将原始指令取出并替换为
Breakpoint,之后将原始指令与同样的另一个 Breakpoint 合并,之后放置在一个
“trampoline” 的区域(也称为 "out-of-line buffer",在 trampoline
区域执行期间必须关闭中断以简化流程)。这样两个 Breakpoint 的存在就能允许
Kprobes 框架即能执行 pre_handler 又能执行
post_handler了。
有趣的是,在 v5.13 以前,x86 的实现并不是在原始指令之后直接跟随 INT3,而是在 INT3 后续的 handler 中将当前模式设置为 Debug 模式,从而实现原始指令执行完后就会立即终止执行并进入名为
do_debug()的 Debug 模式 handler。那这又是为什么呢?可以设想,在原始指令之后添加 INT3 的确看起来和 Debug 模式下单步执行等效,但假如原始指令是一条跳转指令,或者任意会修改
ip register的指令呢?由于下一条执行指令的位置被修改,INT3 会被跳过,因此看起来只能进入 Debug 模式来避免这种场景。参考提交历史,Masami Hiramatsu 在 2021 年提交了修改 x86 single-stepping 的 patch:[RFC PATCH 1/1] x86/kprobes: Use int3 instead of debug trap for single-step 在 email thread 中上述问题被讨论并且给出了结论:在 x86 下 single-stepping 很慢,可以改为原始指令后追加 INT3 的方案。同时,对于会修改
ip的指令,他们参照 arm64 的实现方式,通过 emulation 模拟了部分指令的执行。简单举个例子,假如对于普通指令,第一次进入
do_int3()将执行pre_handler(),之后跳转至 trampoline 执行原始指令,然后再次进入do_int3()后执行post_handler()。而假如原始指令是
jmp,此时在prepare_emulation()中会识别到该指令,并将执行jmp的动作替换为执行一个函数int3_emulate_jmp(),其内容类似regs->ip = new_ip;,这正是jmp指令所做的。在这个情况下,当第一次进入do_int3()并执行pre_handler()之后,不再跳转 trampoline,而是直接执行int3_emulate_jmp()模拟跳转,紧接着执行post_handler()。如此,当从 INT3 返回后,程序会跳转至new_ip处继续运行。
3.4 优化
前面曾提到过,是不是有可能不使用 Breakpoint 这类软件中断,而是直接将切入点位置的指令替换为 jump 指令,从而降低开销呢?事实上 Kprobes 框架的确这么做了,并将这种操作称之为优化(optimization)。
首先我们引用 Kprobes 官方文档中的数据来看看优化前后的开销变化:
1 | k = unoptimized kprobe, b = boosted (single-step skipped), o = optimized kprobe, |
优化能产生数十倍的开销降低,效果令人满意。那么 Kprobes 是如何进行优化的呢?(目前主要是 x86 实现了优化功能,其他体系结构实现了优化逻辑的较少。)
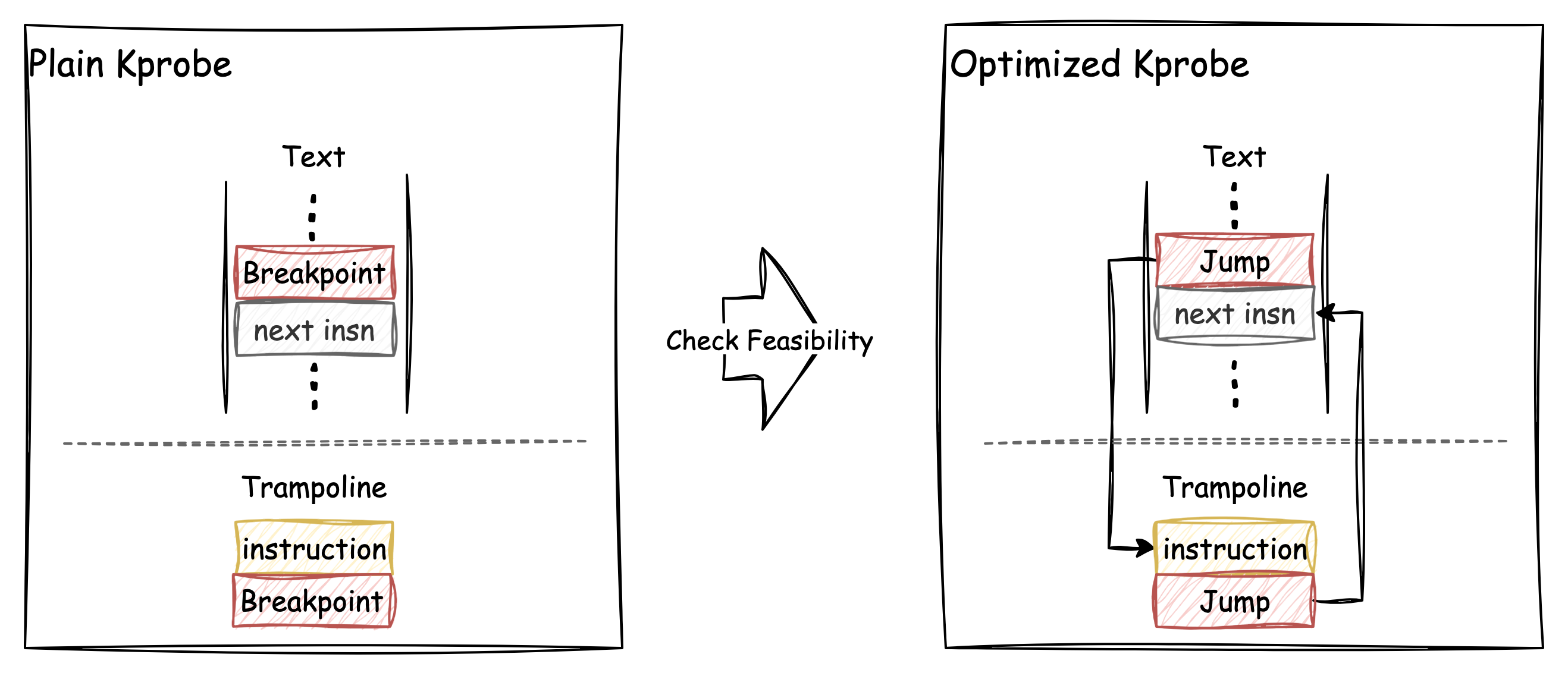
如上图,优化后的效果,是跳转到 trampoline 和跳转回切入点位置的操作全部从 Breakpoint 指令替换为简单的跳转指令。
正因为 Breakpoint 全部替换为了跳转,不再需要处理中断,CPU 的执行流也更简单,这样就减少了包括锁、保存/恢复上下文、iCache 失效、分支预测失败等等的各种开销,因此能极大提升Kprobes 的执行速度。
但并不是任何 Kprobes 都支持优化,优化的限制并不少:
- 被切入函数中不能包含任何间接跳转(indirect jump),因为 x86 jump 指令长度很长(相比 INT3 只占 1 字节),原先的间接跳转有可能跳到 jump 指令中间
- 被切入函数不能包含任何可能导致 exception 的指令,因为 exception handler 在跳回原函数时有可能跳到 jump 指令中间
- 在替换为 jump 指令的区域(称为 optimized region)内不能有 near jump(目标位置在-128~127 bytes 之间),因为直接跳转到 trampoline 的操作没有像 Breakpoint handler 那样处理和调整寄存器的值以适配这种情况
因此在进行 Kprobes 优化前,会先检查各种 pre-condition
是否满足要求,如果都符合要求才会进行优化。并且,为了确保 kprobe
总是可用的,Kprobes 框架在 kprobe 注册时默认会先采用
Breakpoint + single-step
的形式对切入点进行改造,而在注册的最后一步尝试优化,并且即使可优化,也会将优化工作扔到一个工作队列中异步进行。
更详细的流程可见下图:
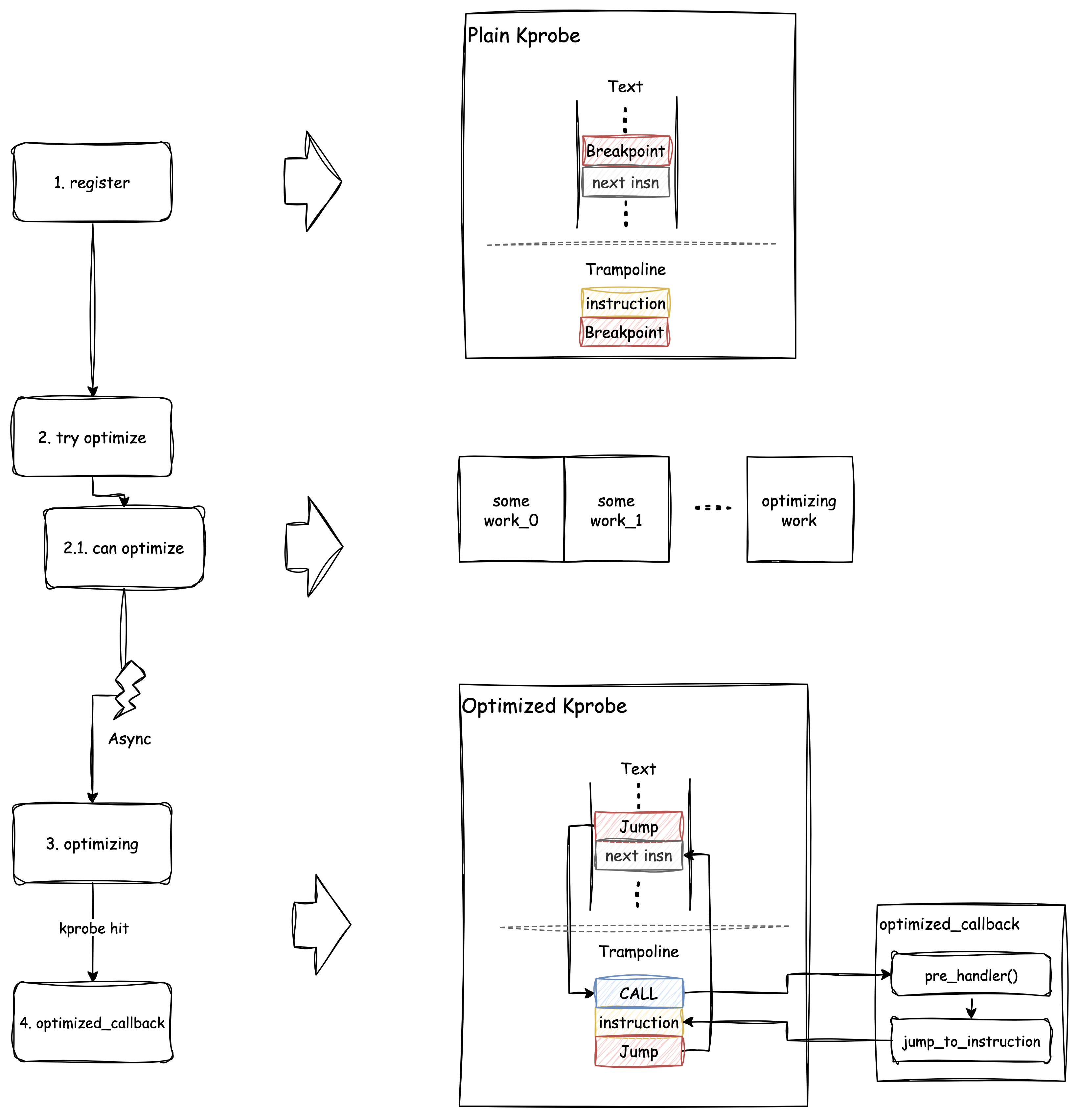
和前面简化的图相比,上图中被优化的 Kprobe 多了一些细节:实际上在
trampoline(out-of-buffer)的起始位置并不直接是原始指令,而是先放置了一个CALL
指令,跳转到 optimized_callback(),在该函数中执行了
pre_handler(),之后才跳回到原始指令继续执行。如果看源码会发现,在执行pre_handler()
的过程中禁止了抢占,这是为了避免可能由抢占而引发的复杂情况如递归调用、随机跳转等。
另外,优化的 Kprobes 也不支持 post_handler,在 Optimized
Kprobes 的前身 djprobe
的设计中,Masami Hiramatsu 提到不支持 post_handler
是基于性能和功能考量下的一种 tradeoff,他最终在二者之间选择了性能。
向前追溯 Kprobe 优化的历史,我们会发现绕不开一位日本的内核开发者:Masami Hiramatsu。Masami 近二十年来一直持续的在为 Kprobes 贡献,并尝试改进其在 x86 的性能。
在 2006 年时,Masami 提交了 “kprobes-booster” 方案,先尝试将 single-step 优化为 jump,该优化将 Kprobes 的执行开销缩短了一半。
之后,他又开发了 djprobe,即 direct jump probe,djprobe 将 Breakpoint 和 single-step 全部替换为了 jump 的方式,这也使其称为 Optimized Kprobe 的前身。
在 djprobe 经过了持续的演进后,2010 年它以 “Optprobe” 的形式合入了内核(见 The Enhancement of Kernel Probing - Kprobes Jump Optimization)。
3.5 黑名单
前面提到过通过直接设置 kprobe.addr
属性可以选择任意的位置作为切入点。然而为了防止不可控,Kprobes
框架限制了一些位置不能被作为切入点。
根据 Kprobes 文档:
Kprobes 能探测大部分 kernel 区域,但除了它自己。这意味着有一些函数是 Kprobes 不能探测的。探测那些函数会导致递归陷阱或者嵌套的 handler 永远无法被调用到。Kprobes 将这些函数以黑名单的形式管理。假如你想将某个函数添加到黑名单中,你只需要(1)将
linux/kprobes.hinclude 进来,然后(2)使用NOKPROBE_SYMBOL()宏来指定一个函数为黑名单函数。Kprobes 会在注册时检查黑名单并在切入点出现在黑名单时拒绝注册。
Kprobes
框架在初始化时会对黑名单进行初始化,而黑名单本质上是一个链表。首先
Kprobes 框架会确保Kprobes 自身的代码段加入黑名单,以防止 Kprobes
自身被探测;其次,对于定义的 “Non-instrumentable”
的代码区域也需要加入黑名单;最后,如同前面引用段落中描述的,用户可以通过
NOKPROBE_SYMBOL()
来自定义黑名单函数,所有的自定义黑名单函数也会被加载到黑名单。
Kprobes 黑名单加载过程中的有趣之处在于自定义黑名单函数:
1 | // include/asm-generic/kprobes.h |
NOKPROBE_SYMBOL()仅仅是定义了一个静态变量持有函数地址,除此之外没有更多操作,特别之处在于
__section("_kprobe_blacklist") 提示编译器将该变量放在
_kprobe_blacklist 段。
然后转到 vmlinus.lds.h:
1 | // include/asm-generic/vmlinus.lds.h |
根据上述链接器头文件中的宏定义,展开后实际上是如下内容:
1 | __start_kprobe_blacklist = .; \ |
这意味着所有被放置在 _kprobe_blacklist 段的内容都会处于
__start_kprobe_blacklist 和
__stop_kprobe_blacklist 之间,因此当我们查看 Kprobes
框架初始化过程中加载黑名单的代码时,就能理解其原理了:
1 | // kernel/kprobes.c |
如上述代码所示,populate_kprobe_blacklist() 会将
__start_kprobe_blacklist 和
__stop_kprobe_blacklist
之间的所有变量都解引用后加入到黑名单中。
3.6 Kretprobes
除了 Kprobes,还有一种 Kretprobes,主要用于在函数返回时添加切入点和 handler。显而易见,假如仅有 Kprobes,我们将很难监控函数的返回动作,因为很多时候函数不止有一个分支路径会 return,将所有 return 位置都注册为切入点对于长函数而言是个灾难。
Kretprobe 专为上述场景设计。其本质原理仍旧是 Kprobes,但相比之下它会在函数入口处注册切入点,当切入点被命中后,Kretprobe 获取到函数的返回地址并保存起来,同时将返回地址替换为 trampoline 地址,从而就实现了函数的所有返回路径都会先经过 trampoline。
1 | // include/linux/kprobes.h |
显然,kretprobe 嵌套了一个
kprobe,并添加了一些额外的 fields 来完成操作。
handler 会在函数返回后执行,这也是 Kretprobes
功能中用户最需要关心的部分。此外 entry_handler
允许用户自定义函数入口被命中后的操作。
maxactive 限定了允许同时触发 Kretprobe
的数量,假如同时触发数超限,那么被忽略的操作数将被累加至
nmissed。
最后,对于返回地址的暂存,当定义
CONFIG_KRETPROBE_ON_RETHOOK 时会采用 rethook
的方式,这也是目前较新的内核版本所推荐的通用方案,而如果不支持就回退到原来的
kretprobe_holder 方案。
4. Reference
[1] Kprobes Document
[3] [RFC PATCH 1/1] x86/kprobes: Use int3 instead of debug trap for single-step
[4] djprobe
[5] kprobes-booster
[6] The Enhancement of Kernel Probing - Kprobes Jump Optimization